IT之家 1 月 6 日音讯,科技媒体 TechPowerUp 今天(1 月 6 日)发布博文,报说念称在 CES 2026 展会期间,英伟达发布了 DGX Spark 和 DGX Station 两款桌面级 AI 超等缱绻机,宣告腹地 AI 劝诱插足“超算时期”。 这两款建筑基于最新的 NVIDIA Grace Blackwell 架构,配备大容量调理内存和 Petaflop(千万亿次)级 AI 性能。 其中枢目标是让路发者、商榷东说念主员和数据科学家无需依赖云霄集群,即可在腹地桌面上劝诱、

IT之家 1 月 6 日音讯,科技媒体 TechPowerUp 今天(1 月 6 日)发布博文,报说念称在 CES 2026 展会期间,英伟达发布了 DGX Spark 和 DGX Station 两款桌面级 AI 超等缱绻机,宣告腹地 AI 劝诱插足“超算时期”。
这两款建筑基于最新的 NVIDIA Grace Blackwell 架构,配备大容量调理内存和 Petaflop(千万亿次)级 AI 性能。
其中枢目标是让路发者、商榷东说念主员和数据科学家无需依赖云霄集群,即可在腹地桌面上劝诱、微调并驱动从 1000 亿到 1 万亿参数的开源及前沿 AI 模子,买通了从腹地原型假想到云霄大领域彭胀的通说念。
DGX Spark:均衡效率与便携看成初学级旗舰,DGX Spark 专为 1000 亿参数级别的模子假想。该系统引入了 NVFP4 数据武艺,能将 AI 模子压缩高达 70% 且不赔本智能发扬。
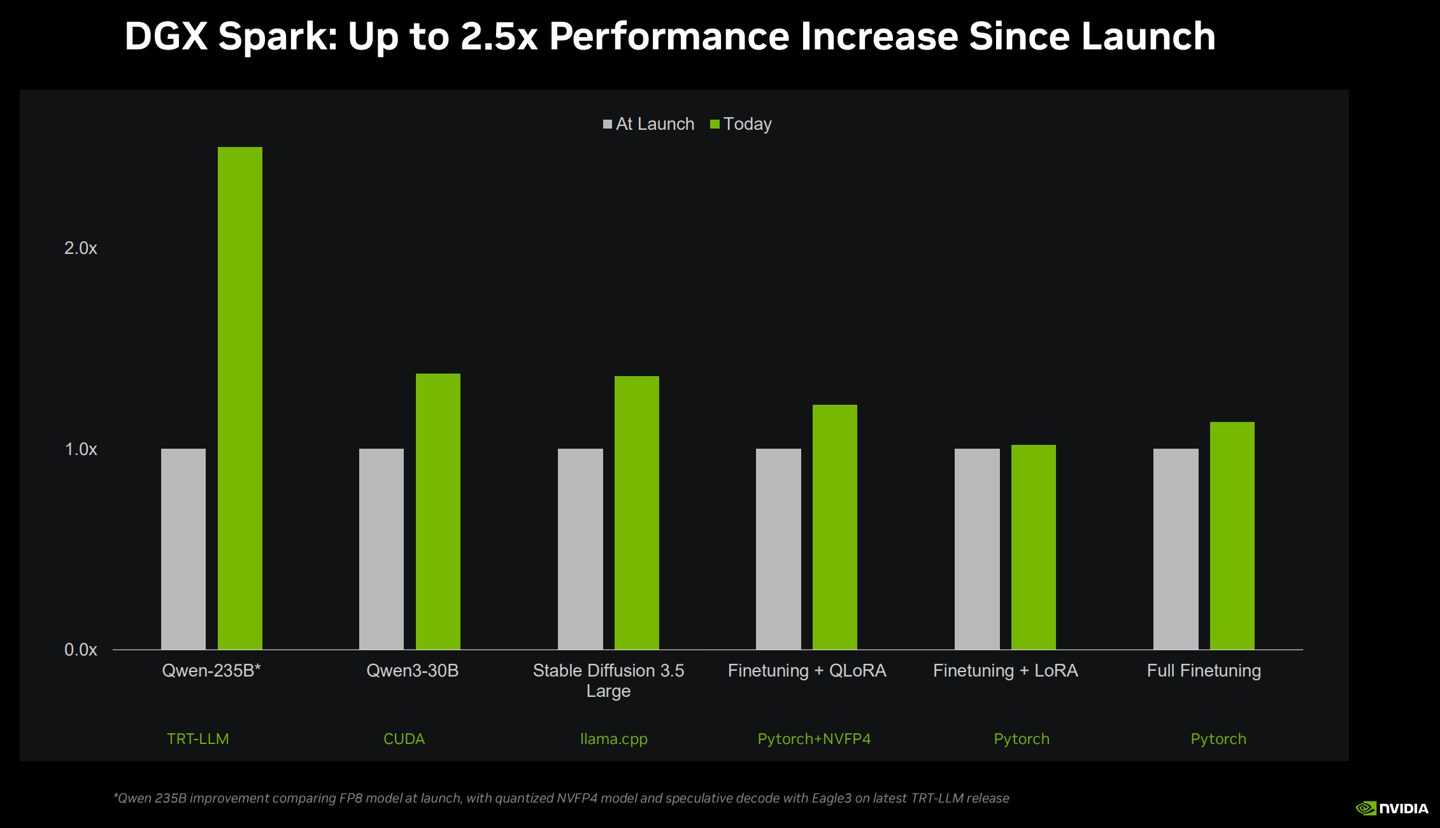
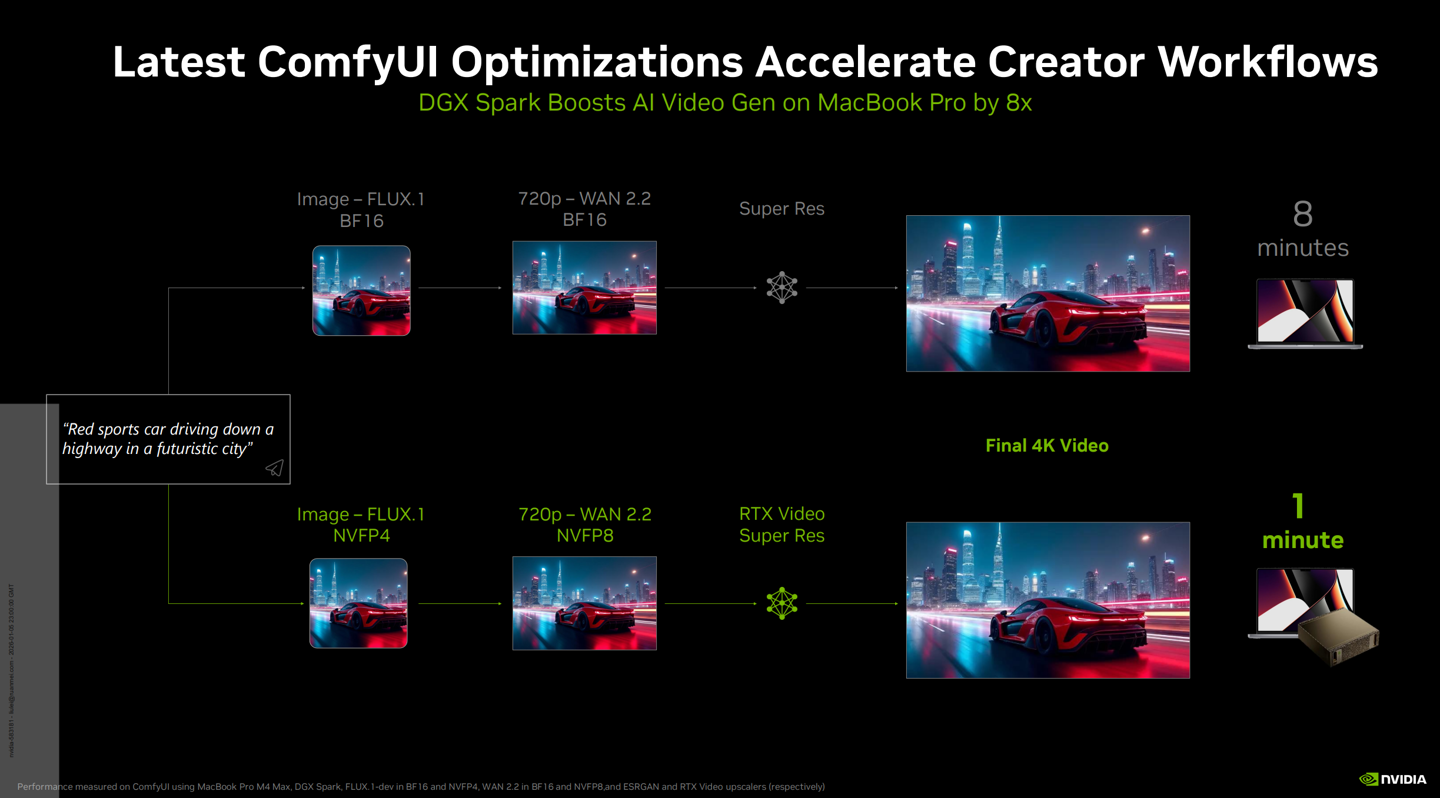
在骨子期骗场景中,DGX Spark 展现了惊东说念主的性能上风:在驱动 Black Forest Labs 的 FLUX.2 等视频生成模子时,其速率比拟搭载 M4 Max 芯片的顶级 MacBook Pro 快了 8 倍。
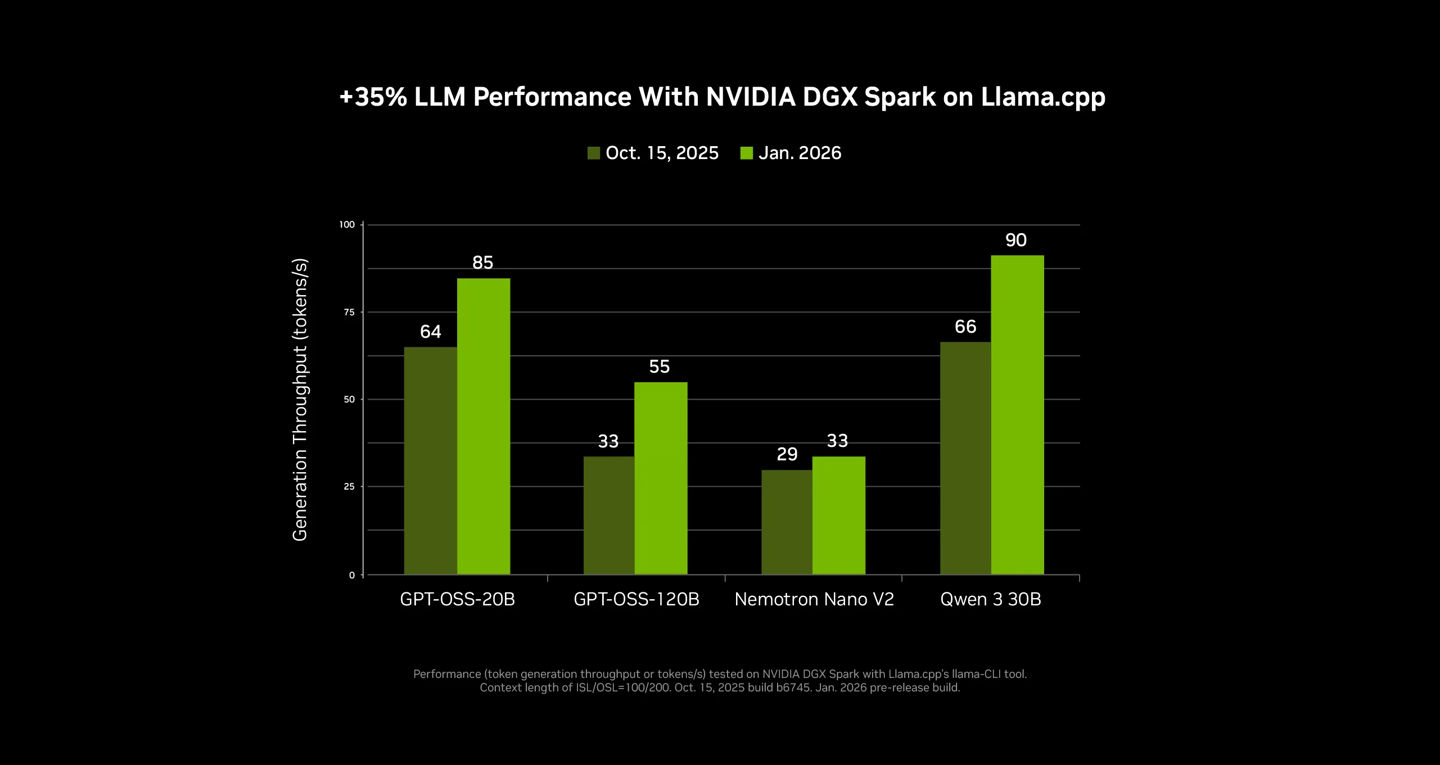
此外,英伟达优化与开源社区(如 llama.cpp)的深度伙同,该系统在驱动 SOTA(起初进)模子时平均性能进步了 35%,并显贵加速了 LLM(废话语模子)的加载速率。
面向企业级和前沿执行室的 DGX Station 则不仅是性能怪兽,更是行业标杆。该机型搭载 GB300 Grace Blackwell Ultra 超等芯片,配备高达 775 GB 的 FP4 精度一致性内存,这一设立让其省略腹地驱动高达 1 万亿参数的巨型模子。
IT之家注:一致性内存(Coherent Memory)指在 CPU 和 GPU 之间分享团结地址空间并兑现硬件级数据同步的架构,通过 2026 年主流的 NVLink-C2C 或 PCIe Gen6/7 互连时间,数据不错在不同惩处器间开脱流动,无需显式的内存拷贝经由,显贵裁汰了延伸。
FP4 精度是一种 4 位浮点武艺(同样遴荐 1 位秀雅、2 位指数、1 位余数的 E2M1 布局),专为 Blackwell 及后续 Rubin 架构优化,能在保握模子精度的前提下,将显存占用裁汰至 FP16 的四分之一,迷糊量进步高达 2-3 倍。
英伟达明确列出了其扶持的一系列前沿模子,包括 Kimi-K2 Thinking、DeepSeek-V3.2、Mistral Large 3、Meta Llama 4 Maverick 以及 OpenAI gpt-oss-120b。
vLLM 中枢改换者 Kaichao You 默示,DGX Station 改变了劝诱动态,让团队能以极低老本在腹地测试 GB300 专属特质。
为了构建竣工的腹地 AI 生态,NVIDIA 晓喻了多项软件与伙同伴伴缱绻。DGX Spark 现已扶持 NVIDIA AI Enterprise 软件栈,并提供了针对机器东说念主(如 Hugging Face Reachy Mini)、基因组学和金融分析的全新劝诱手册(Playbooks)。
在硬件供应方面,DGX Spark 及伙同伴伴推出的 GB10 系统即日起通过戴尔、惠普、联思、华硕等厂商发售体育游戏app平台,而旗舰级的 DGX Station 将于本年晚些时刻负责上市。